Streaming is the new Batch

Data Pipelines, Streaming vs. Batch, the Past, the Present and the Future
Introduction
Data and Analytics continue to gain momentum within the enterprise, rising to the top of the heap of tools that would provide the business with a competitive advantage.
Data Pipelines or how we transfer and transform data within the enterprise is at the heart of building successful data and analytics capabilities that leads to offering powerful and prompt Insights to the business.
There’s a lot of hype surrounding the use of real-time data streams or streaming pipelines instead of batch, however traditionally streaming is used only for a limited set of niche use cases, such as IIoT, fraud detection, trading and Capital Markets, Oil and Gas, …
What has changed then?
To realize the full picture and understand why and how we pick the right tool for the job, we need to go back in time and see how that data pipelines world evolved around us.
The Use Case
To illustrate the evolution of the requirements and the tools, we are going to use a common use case, which is used in many industries.
Order management system, which has many operational and analytical aspects.
A pair of common insights would empower the business in that space, the first is the product/price aggregates to identify the ideal price point and the second is the product/location aggregate to identify the ideal inventory locations.
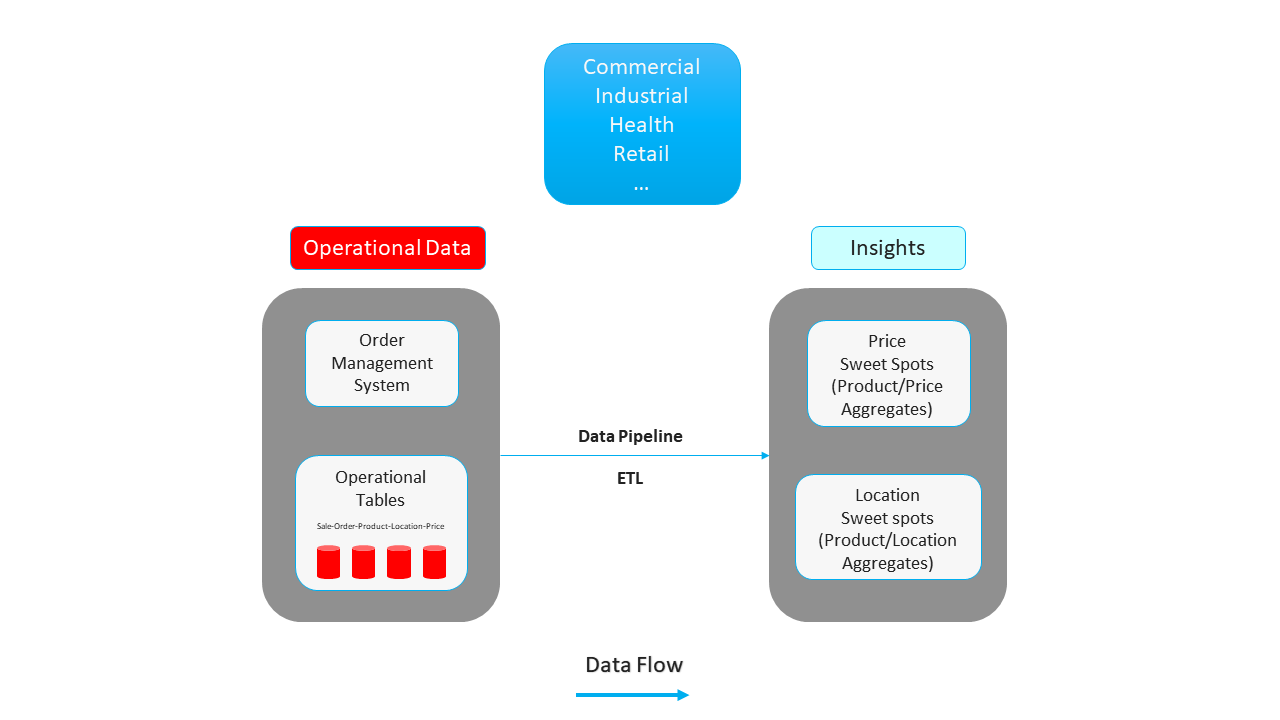
The use case is depicted on Diagram A
The Past
When we take a look back, since 2012+, we can see this; BI and Big Data are at the center stage of the D&A world while Event Streaming was just started.
Traditional ETL
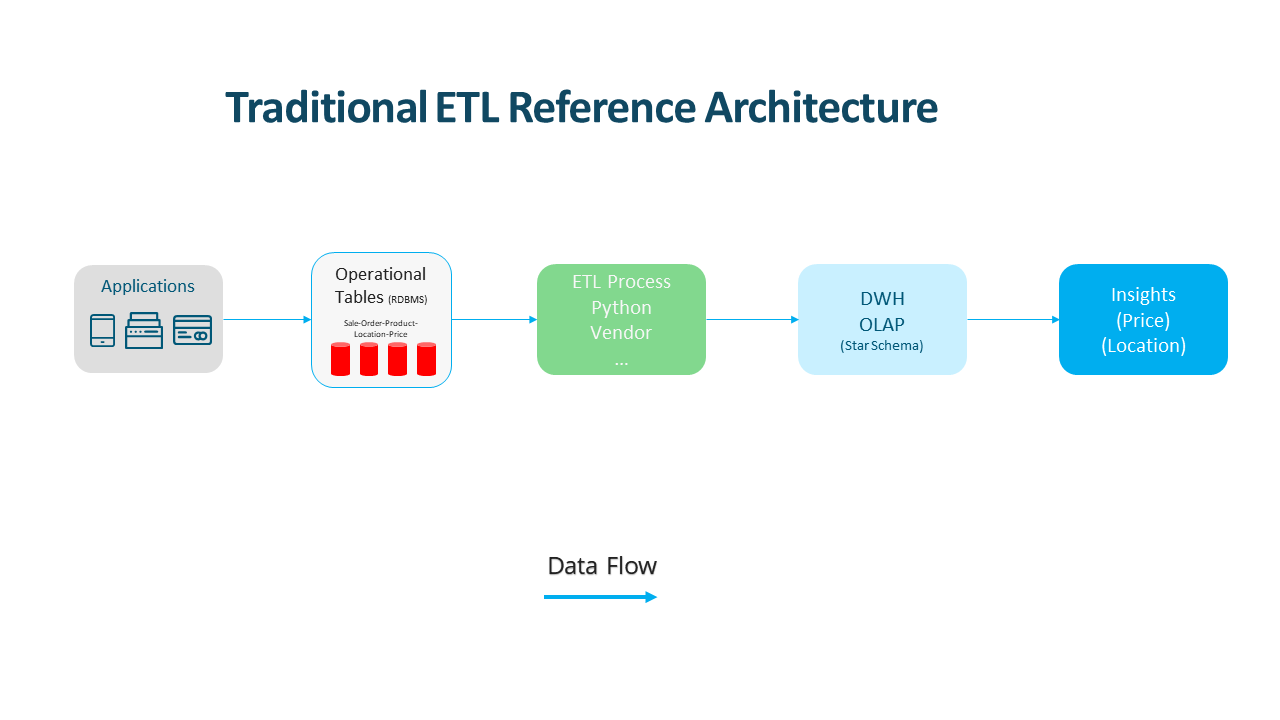
This is the traditional ETL approach, we read data from the source, we run the transformation, de-normalize the data and store it in the warehouse or the OLAP store to make it ready for slicing and dicing.
Event Streaming

Event Streaming is an evolution in Event Driven Architecture, it started to use a journal appending approach and introduced a decentralized model that is focusing on scalability and high availability.
The message read is not a destructive operation anymore and it could be read many times by various consumers.
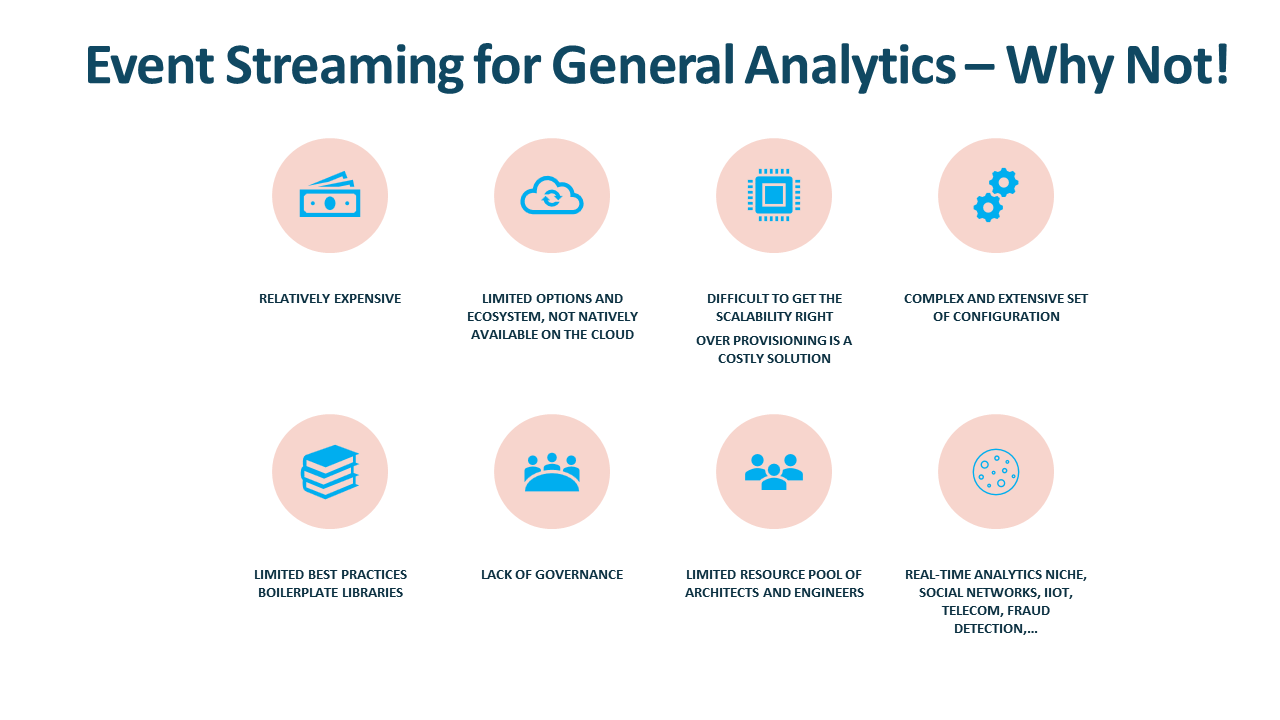
Event Streaming worked well for Reactive Architecture and the Microservices world, supported some niche real-time analytics use cases, but was considered too expensive for traditional ETL, complex to architect, run and maintain and it wasn’t favored by Data Solution Architects or the big data world.
We end up combining both Event Streaming for Operational Microservices Architecture and Analytical ETL Architecture

The Present
The data requirements changed, the applications and the devices exponentially grew in numbers and complexity and so did the data too.
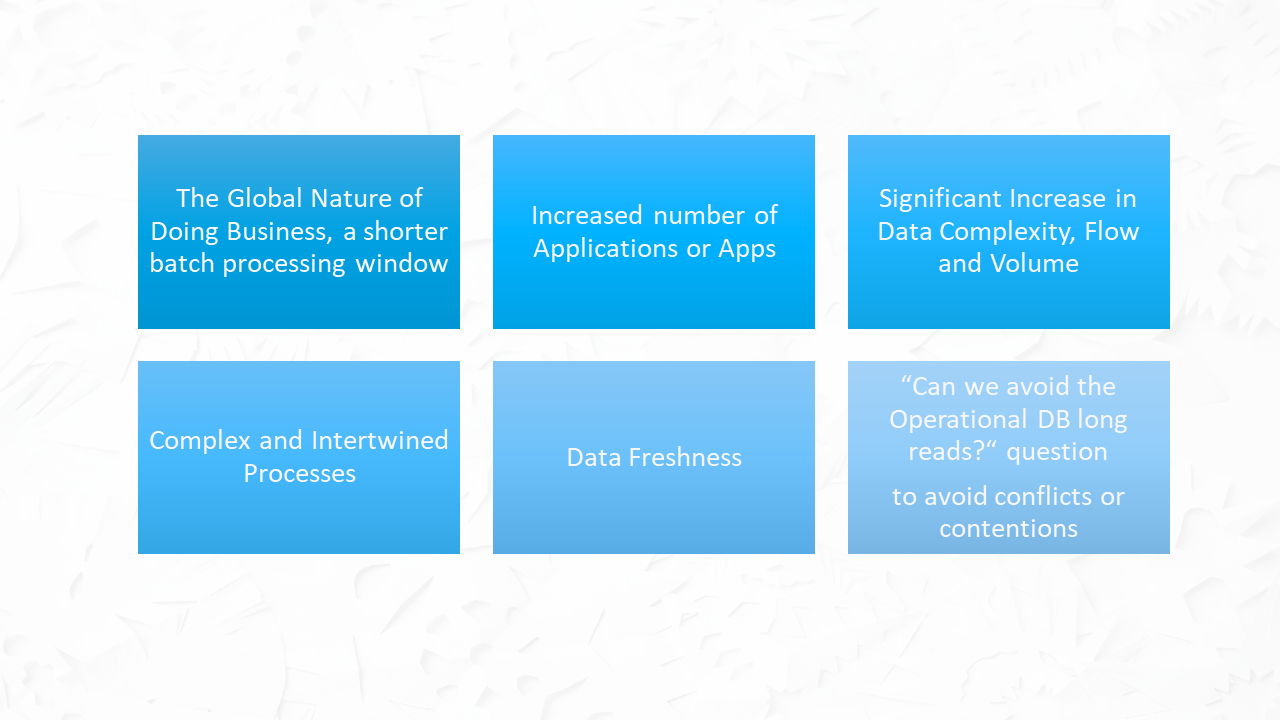
The global nature of doing business and the expectations that businesses would run 24/7 has shortened the batch processing window, while we have been increasingly adding point-to-point integrations, and the growing of the amount of data we need to process, and the complexity of this datasets are not helping either.
The operational world doesn’t want the analytics world to touch the operational tables and impact the performance, and we moved from the traditional ETL to the medallion architecture in the Lakehouse to accommodate those requirements.
In an effort to shorten the open connection time and minimize the extensive read time, we decided to copy the raw data into the bronze layer, reprocess and store in tables in silver and from those tables we create aggregates in Gold, to be ready for consumption as Data Products and Insights of a great value to the business.
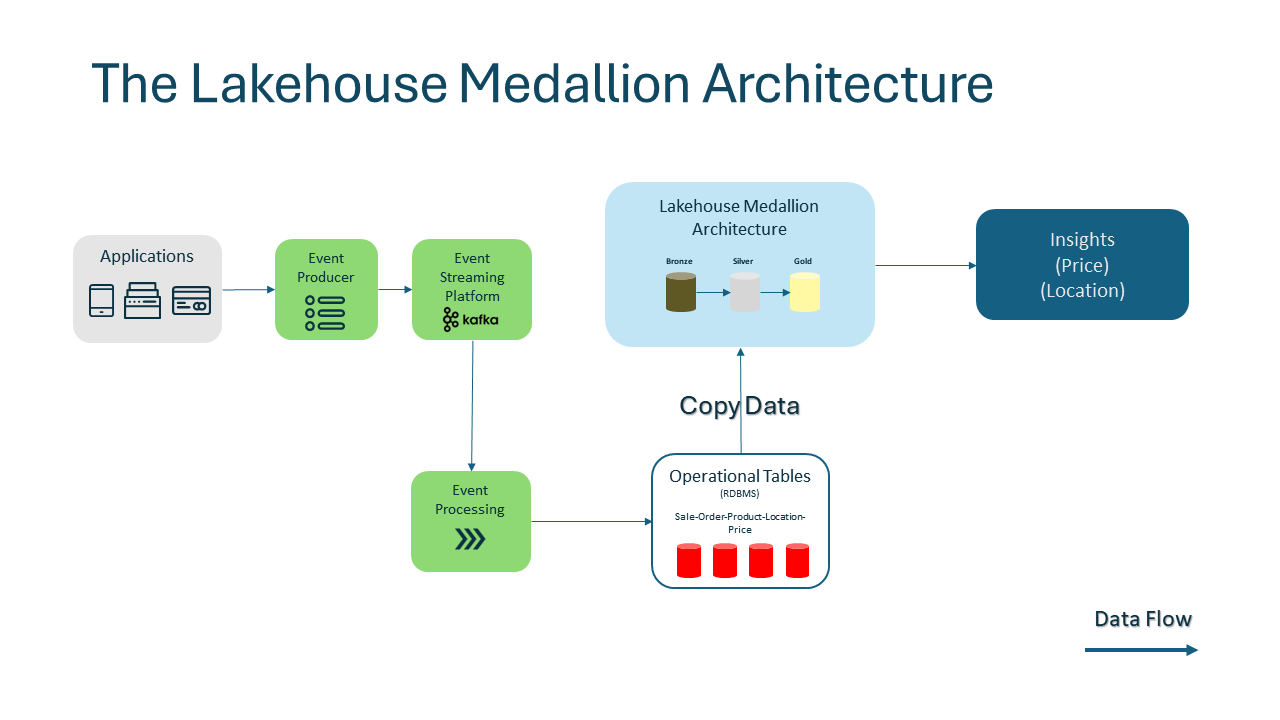
Still, even with this Medallion architecture approach, we still have the operational world resistance and concerns around sharing access to the operational databases.
Can we avoid accessing the operational tables altogether and still feed the OLAP store?
Event Streaming to the Rescue

Using Event Streaming, we will be able to avoid connecting and reading from the operational tables altogether, and write directly into the Lakehouse, even better we can skip the Bronze layer at times and go directly to Silver.
But what happened to all the Data Streaming hurdles we ran into in the past, most of those if not all of them are gone by now, however the stigma persisted.

Event Streaming platforms expanded and flourished in the Cloud, whether native or in the Cloud marketplace such as Confluent Cloud. The Ecosystem is exponentially growing and the barrier to entry for practitioners is getting lower.
Most of the enterprises are using Event Streaming platforms for running complex applications and to support Microservices and SOA Architecture.
The Future
Imagine the power of combining GenAI and real-time context, or how real time data and event streams can empower data sharing and democratization, data are already flowing from the various applications to the Event Stream, by utilizing the existing events we can eliminate many of the time consuming point-to-point contracts and centralization bottlenecks.
Enterprise data governance and data product sharing is extended to the Event Streaming world. World class leaders such as Confluent introduced Event Streaming Governance capabilities, Data Catalogue, Schema Registry, and Data Portal Insights to support this kind of need.
The Conclusion
Those legacy Event Streaming limitations are gone and not stopping us from using the streams pipelines, however that doesn’t mean it’s eliminating the traditional batch, instead, we need to pick the right tool for the job.
For the full presentation, please visit this YouTube link
The Demo
I used the Confluent Cloud environment to demo Event Streaming Governance, the Connectors’ Ecosystem and the Developers’ Ecosystem. You can sign up for the Confluent Cloud trial here.
Also, you can find more cutting-edge Event Streaming and Processing resources there such as Flink.
Learning Resources
Check the Confluent new learning portal here, and the developer portal here.

You must be logged in to post a comment.